Getting started with Industrial DataOps
Industrial companies need contextualized data and a digital architecture that grows with them. Learn how Industrial DataOps helps organizations overcome these challenges.

Key concepts and relationships in Industrial DataOps
DataOps has become an established concept in recent years—but what does it actually mean, and which problems does it solve? This page provides a practical introduction.
The Fourth Industrial Revolution has made one thing clear: production data must do more than simply control processes; it forms the basis for Industry 4.0 applications. Teams across all areas of the business, from quality assurance to maintenance, need access to this data in order to make better decisions more quickly.
However, industrial data often lacks context. It is isolated in files or legacy systems.
Industrial DataOps links this data, makes it accessible and puts it to use.
Data Operations
Data Operations (DataOps) orchestrates people, processes, and technology to deliver secure, reliable, and usable data to those who need it. Originating in IT around 2014, DataOps focuses on improving data quality and reducing the effort required for data preparation.
Industrial DataOps
Industrial DataOps is an emerging discipline that provides flexible data architectures for digital transformation.
In manufacturing environments, it brings together data from various automation and production systems – making it accessible and usable for business users across the enterprise and supply chain.
Data Engineering
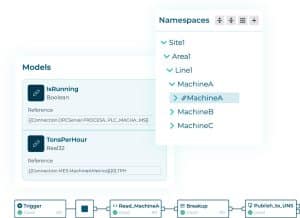
Data engineering is a core component of DataOps. Data engineers build pipelines to collect, transform, and validate data. Using models and pipelines, they standardize and contextualize data, combine multiple sources, and manage data flows, at the edge, on-premise, or in the cloud.
6 signs you need Industrial DataOps

Your digital initiatives are slowing down due to data challenges

Custom cloud scripts make scaling and security difficult

You are incurring high cloud costs for raw data without a clear strategy

You lack visibility into who has access to operational data

Analysts spend more than 50% of their time preparing data

Your OT team is overloaded with requests from business teams
The limits of traditional approaches
Cloud dump
Raw data is pushed into the cloud without processing—expensive, unstructured, and difficult to use.
Custom code
Point-to-point integrations result in countless connections that are hard to maintain.
In-house development
Internally developed solutions are difficult to sustain, as manufacturers are not specialized software vendors.
The HighByte approach to Industrial DataOps
An Industrial DataOps solution for Industry 4.0 requires four key components:
Data orchestration
IT/OT integration, pipelines, and real-time and historical data flows


Data observability
Monitoring and diagnostics for data quality and performance
Data quality
Reliable, consistent, and timely data for compliance and decision-making

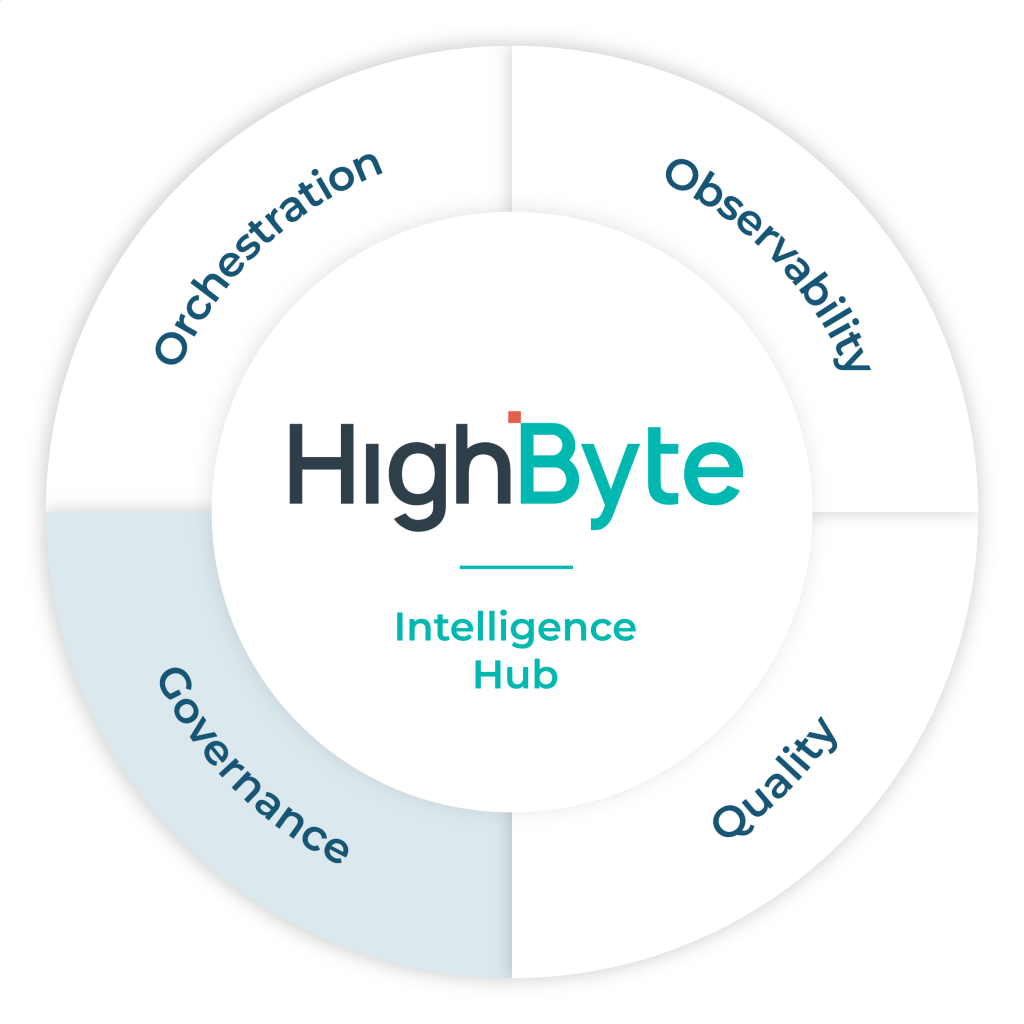
Data governance
Policies and roles for secure and compliant data management
What makes HighByte Intelligence Hub unique
In addition to the four key components above, HighByte Intelligence Hub stands out through:
- System-agnostic: Open, flexible middleware designed to integrate with a wide range of existing IT systems and machines
- Edge-native: Process data where it is generated; add context locally and optimize cloud usage
- Lightweight & No-Code: Easy to deploy, integrate, and maintain; flexible for on-premise or containerized environments
- Scalable: An abstraction layer enables reuse across sites and production lines while improving collaboration and governance
The original version of this page was created by HighByte and is republished and translated here with permission.
You can find the original English version on the HighByte website.

How do you get started with DataOps? Download the 10-step plan.