HighByte 4.1 : de la puissance API pour l’industrie

HighByte a publié la version 4.1 du Intelligence Hub – une version riche en nouvelles fonctionnalités qui fait passer l’Industrial DataOps à la vitesse supérieure. Cette mise à jour met l’accent sur les pipelines de données, la virtualisation des données et une gestion avancée des fichiers. Ces évolutions offrent aux entreprises industrielles encore plus de possibilités pour développer des API de données industrielles flexibles et mettre en œuvre des intégrations efficaces.
Nouveautés dans HighByte Intelligence Hub 4.1
- Industrial Data API Builder
Créez des APIs RESTful et rendez les données industrielles accessibles de manière fluide à des systèmes et applications tiers.
- Mode de débogage des pipelines
Testez directement dans le pipeline et identifiez les problèmes en temps réel, étape par étape.
- Mises à jour de sécurité
Renforcez votre infrastructure de données avec des améliorations pour Snowflake SQL, la connexion Parquet et l’application Web.
- Interface utilisateur améliorée
Navigation et configuration plus rapides grâce à une interface modernisée, plus claire et plus intuitive.
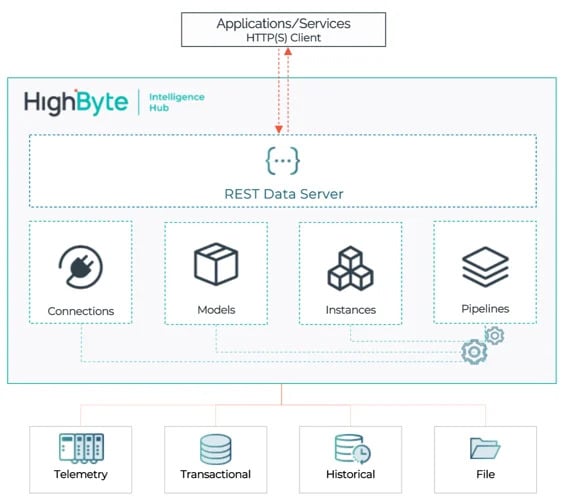
Callable Pipelines : des points de terminaison API dynamiques à la demande
Lorsque plusieurs systèmes, applications et équipes ont besoin d’accéder à des données industrielles, la flexibilité est essentielle. Qu’il s’agisse d’alimenter un ERP via une API, d’envoyer des données vers un Data Lake pour analyse ou de diffuser des données en temps réel vers un message broker – l’accès aux données doit se faire au bon moment.
Dans de nombreux cas, un accès à la demande est essentiel, par exemple :
✅ Un système qualité a besoin de données spécifiques à une étape de production donnée.
✅ Un MES attend certaines conditions externes avant de poursuivre le processus.
✅ De grands volumes de données ne doivent pas être transférés en continu, mais de manière ciblée.
Avec les Callable Pipelines dans HighByte 4.1, il est désormais possible de créer des endpoints API personnalisés pour fournir les données à la demande – en interne via le Intelligence Hub ou en externe via l’API.
Développer et tester les pipelines plus rapidement
Les pipelines de données complexes peuvent désormais être développés plus efficacement : grâce au nouveau mode de débogage des pipelines, les flux de données peuvent être analysés directement dans le Intelligence Hub – sans étapes intermédiaires.
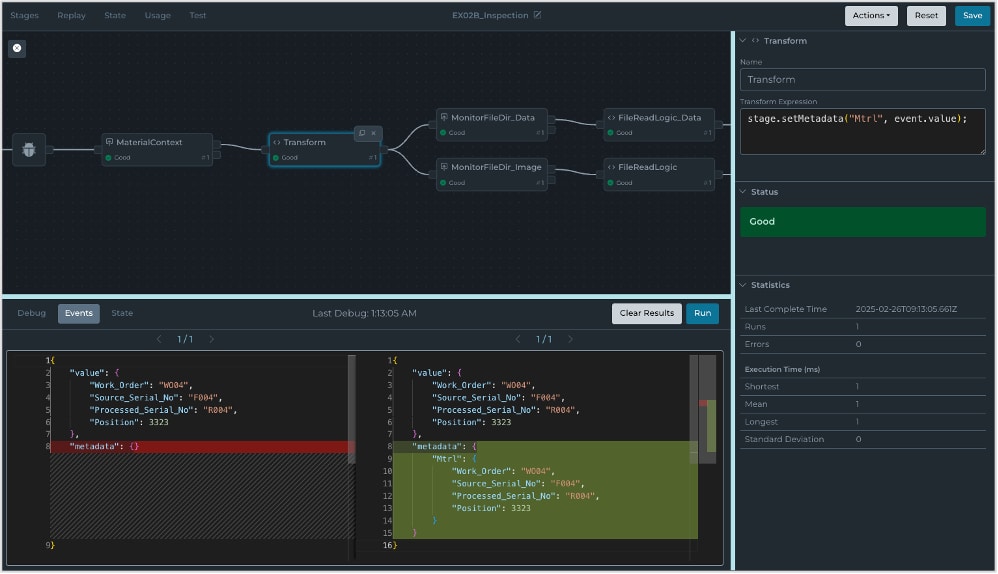
Le mode de débogage des pipelines offre les fonctionnalités suivantes :
✔️ Analyse des effets de différentes configurations et données d’entrée sur le résultat.
✔️ Comparaison des modèles de données avant et après chaque étape de traitement dans le pipeline.
✔️ Identification et correction des erreurs dès les phases de développement et de test.
Sécurité renforcée et meilleure expérience utilisateur
La version 4.1 inclut des mises à jour de sécurité importantes – avec des améliorations pour Snowflake SQL, Parquet et l’application Web. Ces mises à jour assurent un environnement de données plus stable et pérenne.
L’interface utilisateur a également été revue pour offrir une navigation plus fluide et une configuration plus intuitive au quotidien.
Conclusion
HighByte Intelligence Hub 4.1 redéfinit les standards de l’Industrial DataOps. Grâce à de nouveaux outils de développement, des intégrations étendues et des fonctions adaptées aux environnements réglementés, cette version constitue une étape incontournable.
Curieux d’en savoir plus ?
Contactez-nous – nous nous ferons un plaisir de vous présenter
le HighByte Intelligence Hub dans le cadre d’une démo personnelle !