





Pourquoi l’IA dans la production ne fonctionne qu’avec des données propres
Sans données, pas d’IA
L’intelligence artificielle (IA) a besoin de données propres. Cet article montre pourquoi le contexte, la structure et les connexions sont essentiels, et comment les entreprises peuvent correctement construire leur base de données à cette fin.

La qualité des données est essentielle
Les données, goulot d’étranglement de l’intelligence industrielle
L’introduction de l’intelligence artificielle (IA) dans la production industrielle est considérée comme un levier central pour l’efficacité et la compétitivité. Pourtant, une grande partie des initiatives d’IA échouent – non pas en raison des limites techniques des algorithmes, mais souvent en raison d’un manque d’harmonisation avec les objectifs de l’entreprise, d’attentes excessives et, surtout, de la base de données. En effet, de nombreuses données ne sont pas structurées, ne sont pas contextualisées et ne sont pas reliées entre elles. Pour que l’IA puisse apporter une réelle valeur ajoutée, il faut.
- systématiquement structuré,
- enrichi d’informations supplémentaires et
- être intégrées dans l’ensemble du système.
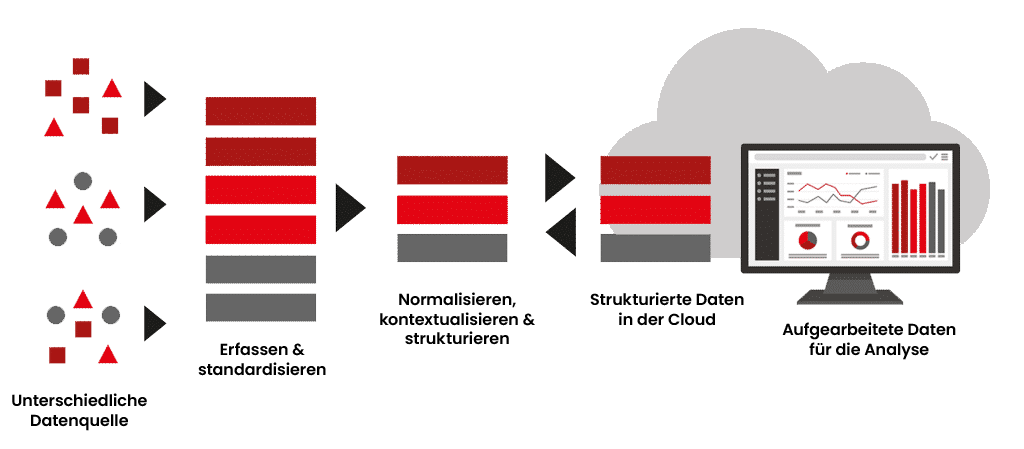
Le défi : qualité des données, silos et absence de contexte

Paysages de données fragmentés
Dans la production, les données sont générées par différents systèmes : Capteurs, API, SCADA, Historian, MES, ERP, LIMS – chaque source a son propre format, protocole et modèle de données. Cette fragmentation rend difficile une vision globale de l’état des machines ou des processus de production.
Résultat : les analyses se basent sur des points de données isolés plutôt que sur une vue d’ensemble cohérente.

Absence de contextualisation des données
De nombreuses usines collectent assidûment des données de capteurs et remplissent des lacs de données. Mais même avec un stockage centralisé, les experts en données passent souvent la majeure partie de leur temps à chercher, préparer et vérifier les informations. Les données sont certes techniquement disponibles, mais elles sont isolées, sans lien avec la machine, le processus ou le moment, et ne sont donc guère exploitables.
Seule une contextualisation précise – c’est-à-dire l’enrichissement par des métadonnées telles que le nom de l’installation, l’état de l’exploitation ou le lot de produits – permet d’obtenir une image globale.

OT/IT-Silos
De nombreuses entreprises restent confrontées au défi de combiner judicieusement la technique opérationnelle (OT) et la technologie de l’information (IT). Alors que les données des machines restent souvent dans les systèmes SCADA, les données de qualité et de processus sont saisies séparément dans l’IT – une coexistence qui entraîne une double conservation des données, des ruptures de médias et une disponibilité limitée.
Parallèlement, le besoin de données intégrées en temps réel augmente. Mais dans les environnements de production sensibles notamment, de nombreuses entreprises hésitent à mettre en œuvre cette solution, par crainte d’un accès incontrôlé ou de nouvelles surfaces d’attaque.
Industrial DataOps
Une approche méthodologique de la fourniture de données industrielles
Industrial DataOps est un concept issu du développement de logiciels et adapté à la mise à disposition de données industrielles. Il combine des principes issus de DevOps, des méthodes agiles, de la fabrication allégée et de la gestion des données afin de créer des pipelines de données rapides, fiables et reproductibles.
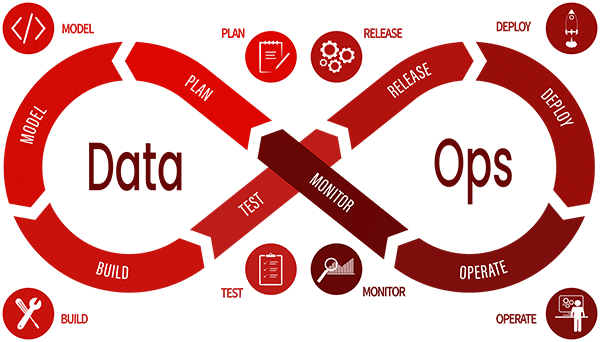
Création de valeur continue grâce à des pipelines de données structurés
La mise à disposition de données n’est pas un projet unique, mais un processus continu qui doit s’adapter avec souplesse aux nouvelles exigences. Une approche qui a fait ses preuves suit un modèle cyclique en huit phases, dont nous aimerions souligner quatre en particulier.
Plan – comprendre et structurer les besoins en données
Tout commence par une analyse : quelles sont les sources de données nécessaires ? Quels sont les processus commerciaux qui doivent être pris en charge ? Au cours de cette phase, les exigences en matière de données sont définies, les modèles de données sont planifiés et les responsabilités sont clarifiées – toujours dans l’optique de l’évolutivité et de la maintenabilité.
Build – Modéliser et intégrer les pipelines de données
Sur la base de la planification, les connexions de données sont établies, les sources intégrées et les flux de données configurés. C’est là qu’interviennent les outils permettant de mettre en œuvre des modèles de données structurés, des contextes et des transformations – idéalement en low code et de manière automatisée.
Release – Préparer les produits de données et les rendre disponibles
Dès que les données sont cohérentes et contextualisées, elles sont transmises aux systèmes cibles : Tableaux de bord, modèles d’intelligence artificielle, entrepôts de données ou systèmes de production. L’assurance qualité est alors importante : la validation, le contrôle des versions et la gouvernance font partie intégrante de la phase de release.
Monitor – Surveiller, adapter, optimiser
Les pipelines de données doivent pouvoir évoluer : nouvelles machines, nouvelles exigences, interfaces modifiées. C’est pourquoi le monitoring est un élément central de DataOps. Les sources d’erreur sont identifiées, les processus sont adaptés – et le cycle recommence.
Industrial DataOps transforme le chaos des données en structures évolutives
Les plateformes industrielles modernes de DataOps relient différentes sources de données OT et IT via des interfaces standardisées. Les données sont traitées dans un système edge, enrichies d’informations contextuelles et transmises de manière structurée – aussi bien à des systèmes locaux comme les SCADA ou les MES qu’à des plateformes cloud modernes pour des analyses ou des applications d’intelligence artificielle.
Grâce à des fonctions telles que l’attribution de points de données (mapping), la reconnaissance automatique des types de données, la synchronisation temporelle des flux de données et l’enrichissement avec des informations contextuelles, on obtient un pipeline continu. Ce pipeline fournit des données fiables et structurées pour des applications modernes telles que les modèles d’intelligence artificielle, les jumeaux numériques ou les circuits de contrôle automatisés.
Un tel système transforme les données incomplètes, doubles ou dispersées en une structure de données fiable et connectable – une base importante pour tout type d’optimisation basée sur les données dans l’industrie.

Use Case
Virtual Conference: DataOps & digital Transformation
Découvrez comment une entreprise innovante utilise les DataOps et les architectures modernes pour réussir sa transformation numérique – des aperçus directement issus de la pratique.
Organisé par IIoT World ; sponsorisé par HighByte.
Conclusion
Pour réussir à utiliser l’IA dans la production, il faut d’abord maîtriser ses données !
L’engouement pour l’intelligence artificielle dans l’industrie est grand – mais sans une base de données solide, contextualisée et intégrée, elle reste une pure fiction. Les entreprises qui introduisent l’IA sans une stratégie DataOps réfléchie investissent dans des solutions fictives. Il faut des structures de données standardisées et modélisées sémantiquement pour obtenir des connaissances réelles à partir des données. Ce n’est qu’en maîtrisant les flux de données, en établissant un contexte de manière automatisée et en supprimant systématiquement les silos que l’on crée les conditions nécessaires à des applications d’IA évolutives, fiables et créatrices de valeur dans la production.
En savoir plus sur DataOps & Co. >

L’architecture industrielle de données en 10 étapes
L’architecture industrielle des données nécessite la coordination des personnes, des processus et des technologies dans le monde entier. Lisez comment faire !
MQTT – Protocole de messagerie légère Publish/Subscribe
Ce protocole populaire est particulièrement adapté au transfert de données depuis des appareils physiques vers le cloud.

Unified Namespace expliqué – fonctionnement & avantages pour l’industrie
L’espace de noms unifié (UNS) crée une structure de données centrale pour une communication transparente et un traitement des données en temps réel. Les processus de production peuvent ainsi être optimisés et les technologies modernes mieux intégrées.






