





Bien démarrer avec le DataOps Industriel
Les entreprises industrielles ont besoin de données contextualisées et d’une architecture numérique qui évolue avec elles. Découvrez comment le DataOps Industriel (Industrial DataOps) aide les entreprises à relever ces défis.

Contexte & glossaire du DataOps Industriel
Au cours des dernières années, le terme DataOps est devenu courant dans les conversations autour des technologies industrielles. Vous vous demandez peut-être ce qu’il signifie et quels problèmes cette approche peut résoudre. Cette page est un bon point de départ.
La quatrième révolution industrielle a montré que les données issues de la production doivent être exploitées au-delà du simple contrôle de processus afin de permettre les cas d’usage de l’Industrie 4.0. Les parties prenantes et systèmes de toute l’entreprise – de la qualité à la maintenance – veulent accéder à ces données pour prendre de meilleures décisions, plus rapidement.
Malheureusement, les données industrielles manquent de contexte et ne sont pas corrélées pour ces usages. Elles sont souvent isolées ou enfermées dans des fichiers ou systèmes hérités. La clé pour libérer ces données, c’est le DataOps Industriel.
Data Operations
Les Data Operations (ou DataOps) orchestrent les personnes, processus et technologies afin de livrer de façon sécurisée des données fiables et prêtes à l’emploi à tous les systèmes et utilisateurs qui en ont besoin. Né dans l’IT en 2014, le DataOps propose une approche d’intégration et de sécurisation des données qui vise à améliorer leur qualité et à réduire le temps consacré à leur préparation pour l’analyse.
Industrial DataOps
Industrial DataOps (DataOps Industriel) est une discipline relativement nouvelle qui répond aux besoins croissants des entreprises industrielles en matière d’architecture de données, dans leur transformation numérique. Ces solutions sont nécessaires dans les environnements de production où les données doivent être agrégées à partir de systèmes et d’équipements d’automatisation industrielle hétérogènes, puis exploitées par les utilisateurs métiers de l’entreprise et de sa chaîne d’approvisionnement.
Data Engineering
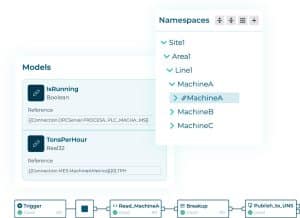
L’ingénierie des données est un pilier du DataOps. Les data engineers construisent des pipelines pour collecter, transformer et valider les données en mouvement. Avec des outils comme les modèles et pipelines, ils peuvent standardiser et contextualiser les données industrielles, fusionner des sources multiples et orchestrer les flux de données vers les applications consommatrices, qu’elles s’exécutent à la périphérie (Edge), sur site ou dans le Cloud.
6 signes qu’il est temps d’évaluer le DataOps Industriel

Vos projets de transformation numérique stagnent à cause de problèmes d’interopérabilité des données.

Vous développez et maintenez des scripts personnalisés pour envoyer vos données industrielles vers le Cloud, limitant évolutivité, agilité et sécurité.

Vous payez des frais élevés et variables de stockage Cloud pour des données brutes, sans stratégie claire d’utilisation.

Vous ne savez pas exactement quels utilisateurs internes et externes ont accès aux données opérationnelles.

Vos analystes passent plus de 50 % de leur temps à rechercher, corriger et préparer les données pour les analytiques.

L’équipe OT est surchargée de demandes des différents services pour accéder aux données et les interpréter.
Les limites des approches traditionnelles
Cloud dump
Beaucoup d’entreprises tentent de transférer toutes leurs données brutes dans le Cloud sans traitement préalable. Résultat : une masse de données chaotique, non structurée, coûteuse et difficile à exploiter.
Code personnalisé fragile
Certaines entreprises développent des intégrations point-à-point spécifiques à leurs sources de données industrielles. Le résultat est des centaines d’intégrations cachées dans du code, impossibles à maintenir à long terme.
Solutions internes artisanales
D’autres essaient de créer leurs propres systèmes logiciels internes d’intégration de données. Mais n’étant pas éditeurs de logiciels, ces fabricants peinent à maintenir ces solutions dans le temps.
L’approche HighByte du Industrial DataOps
Il existe une meilleure voie. Pour répondre aux besoins de votre infrastructure Industrie 4.0, une solution d’Industrial DataOps doit offrir quatre composants clés :
Orchestration des données
Connexion IT/OT complète, pipelines de données, gestion de flux en temps réel, transactionnels ou historiques.


Observabilité des données
Surveillance et diagnostic en continu pour assurer la qualité et la performance des pipelines.
Qualité des données
Fiabilité, exactitude, cohérence et rapidité : des données de haute qualité pour la conformité et la prise de décision.

Gouvernance des données
Politiques, rôles et responsabilités pour administrer les données de manière sécurisée et conforme.
Pourquoi HighByte Intelligence Hub est unique
En plus des quatre piliers ci-dessus, voici ce qui distingue HighByte Intelligence Hub :
- Indépendant des systèmes : middleware ouvert et agnostique, conçu pour s’intégrer avec un large éventail de systèmes d’information et machines existants.
- Natif Edge : gestion des données au plus près de leur création, avec contextualisation sur le terrain et optimisation des coûts Cloud.
- Léger & sans code : facile à installer, intégrer et maintenir ; flexible et déployable sur site ou en conteneur.
- Conçu pour être déployé à l’échelle : une couche d’abstraction qui permet de répliquer le travail d’ingénierie entre sites et lignes de production, sans « réinventer la roue » et en optimisant collaboration et gouvernance.
Partagez nous votre projet, vos challenges et vos questions. Retour sous 24h!
*Requis

Jérôme Banuls
Directeur Développement Commercial
La version originale de cette page a été créée par HighByte et est republiée et traduite ici avec l’autorisation de HighByte. Consultez la version originale en anglais sur le site web de HighByte.

Nouveau dans le DataOps ? Téléchargez cette brochure en 10 étapes !
Découvrez pourquoi le DataOps est la clé de l’IA industrielle.