Warum KI in der Produktion erst mit sauberen Daten funktioniert
Ohne Daten keine KI
Künstliche Intelligenz (KI) braucht saubere Daten. Dieser Beitrag zeigt, warum Kontext, Struktur und Verbindung entscheidend sind – und wie Unternehmen ihr Datenfundament dafür richtig aufbauen.

Datenqualität ist entscheidend
Daten als Engpass der industriellen Intelligenz
Die Einführung von Künstlicher Intelligenz (KI) in der industriellen Fertigung gilt als zentraler Hebel für Effizienz und Wettbewerbsfähigkeit. Dennoch scheitert ein Grossteil der KI-Initiativen – nicht wegen technischer Grenzen der Algorithmen, sondern oft an fehlender Abstimmung mit den Unternehmenszielen, überzogenen Erwartungen und vor allem an der Datenbasis. Denn viele Daten sind unstrukturiert, kontextlos und nicht miteinander verknüpft. Damit KI echten Mehrwert liefern kann, müssen sie
- systematisch strukturiert,
- mit Zusatzinformationen angereichert und
- systemübergreifend integriert werden.
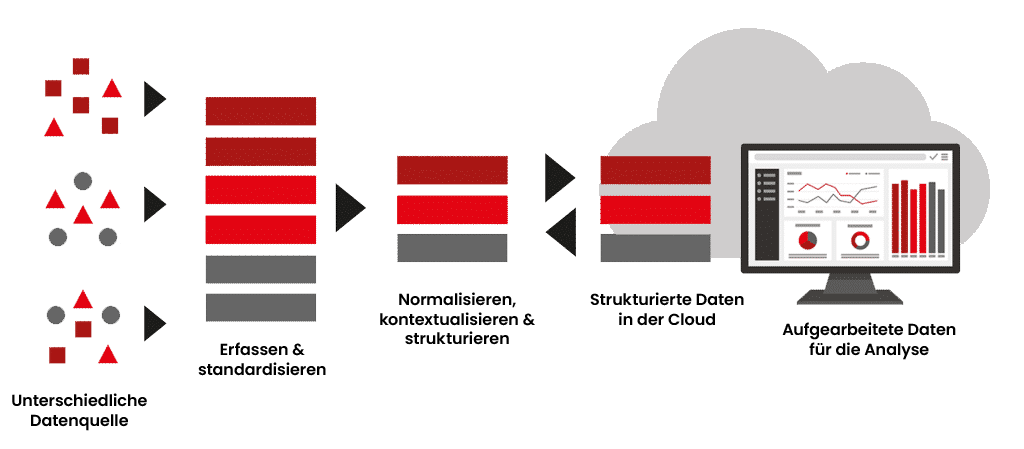
Die Herausforderung: Datenqualität, Silos und fehlender Kontext

Fragmentierte Datenlandschaften
In der Produktion fallen Daten in verschiedenen Systemen an: Sensoren, SPS, SCADA, Historian, MES, ERP, LIMS – jede Quelle hat ihr eigenes Format, Protokoll und Datenmodell. Diese Fragmentierung erschwert eine ganzheitliche Sicht auf Maschinenzustände oder Produktionsprozesse.
Die Folge: Analysen basieren auf isolierten Datenpunkten, statt auf einem konsistenten Gesamtbild.

Fehlende Datenkontextualisierung
Viele Fabriken sammeln fleissig Sensordaten und füllen Data Lakes. Doch auch bei zentraler Speicherung verbringen Datenexperten oft den Grossteil ihrer Zeit mit dem Suchen, Aufbereiten und Prüfen von Informationen. Die Daten liegen zwar technisch verfügbar vor, sind aber ohne Bezug zu Maschine, Prozess oder Zeitpunkt isoliert und damit kaum verwertbar.
Erst durch eine präzise Kontextualisierung – also die Anreicherung mit Metadaten wie Anlagenname, Betriebsstatus oder Produktcharge – entsteht ein ganzheitliches Bild.

OT/IT-Silos
Viele Unternehmen stehen weiterhin vor der Herausforderung, operative Technik (OT) und Informationstechnologie (IT) sinnvoll zu verknüpfen. Während Maschinendaten oft in SCADA-Systemen verbleiben, werden Qualitäts- und Prozessdaten getrennt in der IT erfasst – ein Nebeneinander, das zu doppelten Datenhaltungen, Medienbrüchen und eingeschränkter Verfügbarkeit führt.
Gleichzeitig steigt der Bedarf an integrierten Echtzeitdaten. Doch gerade in sensiblen Produktionsumgebungen zögern viele Unternehmen mit der Umsetzung, aus Sorge vor unkontrollierten Zugriffen oder neuen Angriffsflächen.
Industrial DataOps
Ein methodischer Ansatz für industrielle Datenbereitstellung
Industrial DataOps ist ein Konzept aus der Softwareentwicklung, das für die industrielle Datenbereitstellung adaptiert wurde. Es kombiniert Prinzipien aus DevOps, agilen Methoden, Lean Manufacturing und Datenmanagement, um schnelle, zuverlässige und reproduzierbare Datenpipelines zu schaffen.
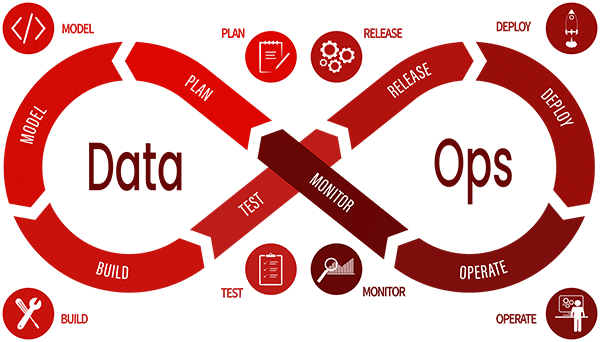
Kontinuierliche Wertschöpfung durch strukturierte Datenpipelines
Datenbereitstellung ist kein einmaliges Projekt, sondern ein fortlaufender Prozess, der sich flexibel an neue Anforderungen anpassen muss. Ein bewährter Ansatz folgt dabei einem zyklischen Modell mit acht Phasen, von denen wir vier speziell hervorheben möchten.
Plan – Datenbedarf verstehen und strukturieren
Am Anfang steht die Analyse: Welche Datenquellen werden benötigt? Welche Geschäftsprozesse sollen unterstützt werden? In dieser Phase werden Datenanforderungen definiert, Datenmodelle geplant und Verantwortlichkeiten geklärt – immer mit Blick auf Skalierbarkeit und Wartbarkeit.
Build – Datenpipelines modellieren und integrieren
Auf Basis der Planung werden Datenverbindungen aufgebaut, Quellen integriert und Datenströme konfiguriert. Hier kommen Tools zur Anwendung, mit denen sich strukturierte Datenmodelle, Kontexte und Transformationen umsetzen lassen – idealerweise Low-Code und automatisiert.
Release – Datenprodukte bereitstellen und verfügbar machen
Sobald die Daten konsistent und kontextualisiert vorliegen, werden sie an Zielsysteme übergeben: Dashboards, KI-Modelle, Data Warehouses oder Produktionssysteme. Wichtig ist dabei die Qualitätssicherung: Validierung, Versionskontrolle und Governance gehören fest zur Release-Phase.
Monitor – Überwachen, anpassen, optimieren
Datenpipelines müssen sich verändern können: neue Maschinen, neue Anforderungen, geänderte Schnittstellen. Deshalb ist Monitoring ein zentraler Bestandteil von DataOps. Fehlerquellen werden identifiziert, Prozesse angepasst – und der Zyklus beginnt von vorn.
Industrial DataOps transformiert das Datenchaos in skalierbare Strukturen
Moderne Industrial-DataOps-Plattformen verbinden verschiedene OT- und IT-Datenquellen über standardisierte Schnittstellen. Die Daten werden in einem Edge-System verarbeitet, mit Kontextinformationen angereichert und strukturiert weitergegeben – sowohl an lokale Systeme wie SCADAs oder MES als auch an moderne Cloud-Plattformen für Analysen oder KI-Anwendungen.
Durch Funktionen wie das Zuordnen von Datenpunkten (Mapping), die automatische Erkennung von Datentypen, die zeitliche Synchronisierung von Datenströmen und der Anreicherung mit kontextuellen Informationen entsteht eine durchgängige Pipeline. Diese Pipeline liefert verlässliche und strukturierte Daten für moderne Anwendungen wie KI-Modelle, digitale Zwillinge oder automatisierte Regelkreise.
Ein solches System wandelt unvollständige, doppelte oder verstreute Daten in eine zuverlässige und anschlussfähige Datenstruktur um – eine wichtige Grundlage für jede Art von datenbasierter Optimierung in der Industrie.

Use Case
Virtual Conference: DataOps & digitale Transformation
Erfahren Sie, wie ein innovatives Unternehmen DataOps und moderne Architekturen nutzt, um die digitale Transformation erfolgreich umzusetzen – Einblicke direkt in die Praxis.
Organisiert von IIoT World; gesponsert von HighByte.
Fazit
Wer KI erfolgreich in der Produktion einsetzen will, muss zuerst seine Daten in den Griff bekommen!
Der Hype um Künstliche Intelligenz in der Industrie ist gross – doch ohne eine belastbare, kontextualisierte und integrierte Datenbasis bleibt er reine Fiktion. Unternehmen, die KI ohne eine durchdachte DataOps-Strategie einführen, investieren in Scheinlösungen. Es braucht semantisch modellierte, standardisierte Datenstrukturen, um aus Daten tatsächliche Erkenntnisse zu gewinnen. Nur wer Datenflüsse beherrscht, Kontext automatisiert aufbaut und Silos konsequent abbaut, schafft die Voraussetzungen für skalierbare, vertrauenswürdige und wertschöpfende KI-Anwendungen in der Produktion.
Erfahren Sie mehr über DataOps & Co. >

Unified Namespace erklärt – Funktionsweise & Vorteile für die Industrie
Der Unified Namespace (UNS) schafft eine zentrale Datenstruktur für nahtlose Kommunikation und Echtzeit-Datenverarbeitung. So können Produktionsprozesse optimiert und moderne Technologien besser integriert werden.

Industrielle Datenarchitektur: In 10 Schritten zu einer skalierbaren Lösung
Die industrielle Datenarchitektur erfordert die Koordination von Personen, Prozessen und Technologien weltweit. Lesen Sie, wie es geht!
MQTT – leichtgewichtiges Publish/Subscribe-Messaging-Protokoll
Das beliebte Protokoll eignet sich insbesondere für die Übertragung von Daten aus physischen Geräten in die Cloud.