





Version 4.4 : Espaces de noms fédérés et pipelines pilotés par l’IA

Les données industrielles ont toujours été difficiles à exploiter. L’intégration numérique des processus métiers, dans une quête de productivité, tend même à accentuer cette difficulté. À mesure que les organisations connectent davantage de systèmes, dans toujours plus de directions, les exigences imposées aux données se multiplient à chaque intégration.
L’écart entre ce pour quoi les systèmes existants ont été conçus et ce dont les organisations ont besoin aujourd’hui est bien réel. Les données réparties entre zones, sites et réseaux sont difficiles à contextualiser et à exploiter comme un ensemble unifié. Et à mesure que les déploiements s’étendent et que davantage d’équipes sont impliquées, la connaissance derrière les pipelines de données doit devenir plus accessible — non seulement pour les ingénieurs qui les ont conçus à l’origine, mais aussi pour les équipes plus larges qui les utilisent et les maintiennent au quotidien.
HighByte Intelligence Hub version 4.4 a été conçu précisément pour cet environnement. Cette version introduit les Données Centrales pour composer des espaces de noms fédérés et des pipelines avec des sources de données distantes, de nouvelles options de connectivité incluant le support natif de Databricks Zerobus et l’interface serveur CESMII i3X, ainsi qu’un Agent IA pour les Pipelines qui rend leur configuration plus accessible, quels que soient les profils et les niveaux de compétence. Ensemble, ces évolutions élargissent à la fois ce que les équipes Industrial DataOps peuvent faire, et qui peut le faire.
Cet article présente chacune de ces fonctionnalités et ce qu’elles rendent possible.
Données centrales : un plan de données fédéré à travers systèmes et réseaux
Les données industrielles ne naissent ni ne résident en un seul endroit. Elles sont distribuées entre sites, zones, systèmes et réseaux. Pourtant, les applications, services et utilisateurs qui en dépendent doivent pouvoir y accéder comme si elles se trouvaient en un point unique. Les organisations industrielles souhaitent modéliser, contextualiser et faire circuler leurs données de manière globale. La nature distribuée de ces données rend toutefois cet objectif difficile à atteindre de façon unifiée et maîtrisée.
Pour répondre à ce défi, la version 4.4 introduit les Données Centrales, ainsi qu’un nouveau mécanisme interne de souscription.
Données centrales
Depuis la version 3.0, Intelligence Hub intègre la Configuration Centrale, permettant de connecter de manière sécurisée des hubs distants à un hub central et d’en gérer la configuration. Depuis l’introduction des espaces de noms (Namespaces) en version 4.0, les utilisateurs ont demandé des moyens de fédérer les espaces de noms des hubs distants dans un hub central. La version 4.4 répond à cette attente avec les Données Centrales.
Les Données Centrales étendent le concept de Configuration Centrale en exposant le plan de données d’un hub vers un hub central. Une fois connectés, le hub central peut visualiser l’espace de noms de chaque hub distant et mapper ses nœuds dans un espace de noms central. Les utilisateurs peuvent parcourir cet espace de noms, exécuter des Smart Queries et construire des pipelines qui s’abonnent à des sources de données distantes et les exploitent comme si elles étaient locales.
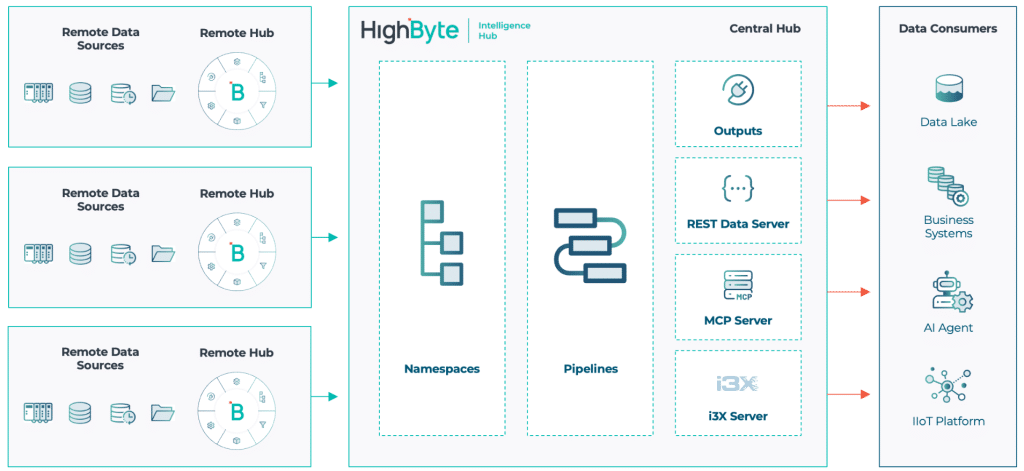
Données Centrales dans HighByte Intelligence Hub version 4.4
Pour illustrer concrètement : un seul pipeline peut exécuter une Smart Query à travers des jeux de données contextualisés provenant de plusieurs hubs distants, s’abonner à des mesures pertinentes pour de la maintenance conditionnelle, transformer les données pour correspondre à l’API MaintainX et publier directement vers MaintainX — le tout depuis un hub unique agissant pour le compte de nombreuses sources de données distribuées, à travers des frontières réseau.
Les Données Centrales simplifient les architectures distribuées en permettant à un ensemble commun de pipelines de servir des cibles de données à l’échelle de l’entreprise depuis un hub unique, avec l’ensemble des données d’usine modélisées, découvrables et exploitables à la demande.
Souscriptions internes
Intelligence Hub supporte l’abonnement à des sources événementielles telles qu’OPC UA et MQTT depuis sa première version. Toutefois, à mesure que les modèles de données et les pipelines gagnent en sophistication, le besoin de s’abonner aux changements au sein d’objets complexes — comme les instances de modèles, qui peuvent combiner des sources événementielles et non événementielles — s’est accentué.
La version 4.4 introduit la prise en charge des souscriptions pour des objets complexes, y compris les Instances, les Espaces de noms, ainsi que les branches et collections OPC UA. Grâce à de nouveaux déclencheurs de pipelines, des événements sont automatiquement générés lorsque les données sources sous-jacentes évoluent. Par exemple, si une instance est composée de tags OPC UA et de données SQL, un événement est créé lors d’un changement des tags OPC UA, et la charge utile inclut les valeurs les plus récentes issues de SQL. Les souscriptions fonctionnent également au niveau des espaces de noms — y compris les nœuds fédérés via les Données Centrales — et génèrent des événements à chaque modification de valeur.
Cette nouvelle capacité simplifie la conception des pipelines, élimine la nécessité de scruter périodiquement les changements et garantit qu’aucune évolution de données n’est manquée, qu’elle soit locale ou distribuée.
Faire progresser la connectivité industrielle
L’écosystème des données industrielles est façonné par les plateformes clés dans lesquelles les organisations ont investi, ainsi que par les standards ouverts qui définissent la manière dont les systèmes se connectent. La profondeur d’intégration avec ces plateformes — de l’ingestion en masse ou en streaming jusqu’à l’accès par requêtes ou agents — fait la différence entre une connectivité superficielle et un impact réel.
Les standards ouverts sont tout aussi essentiels, car ils réduisent le travail non différenciant et le coût total de possession pour l’ensemble des acteurs.
Être leader en matière de connectivité suppose d’anticiper sur ces deux fronts : soutenir les plateformes où le travail s’effectue réellement et promouvoir des standards ouverts conduisant à une adoption concrète. La version 4.4 répond à ces deux enjeux.
Databricks Zerobus
Databricks est devenu l’une des plateformes les plus largement adoptées pour l’analytique et les charges de travail basées sur l’IA. Intelligence Hub propose une intégration complète couvrant l’ensemble des modes d’interaction. Pour l’ingestion, il supporte le chargement en masse via le stockage objet ainsi que l’ingestion directe via la connexion Databricks Storage. Pour les requêtes et le reverse ETL, la connexion Databricks SQL permet un accès direct depuis Databricks vers les systèmes OT. L’ingestion en streaming était également prise en charge, mais nécessitait auparavant le passage par un service intermédiaire de streaming d’événements, comme Amazon Kinesis Data Streams, Azure Event Hubs ou Apache Kafka, avant d’atteindre Databricks.
Databricks Zerobus change cette approche. Il s’agit d’une nouvelle interface serverless d’ingestion en streaming qui permet l’ingestion des données, en continu et enregistrement par enregistrement, directement dans des tables Delta. La version 4.4 introduit une connexion Zerobus native dans Intelligence Hub, permettant une ingestion en streaming directe et à faible latence vers Databricks, sans service intermédiaire. Les tables sont créées automatiquement et les schémas évoluent en fonction des définitions de modèles. Les données arrivent directement dans Delta Lake et sont immédiatement visibles dans Unity Catalog.

Intégrations Databricks directes dans HighByte Intelligence Hub version 4.4
Avec cette nouvelle connexion Databricks Zerobus, Intelligence Hub couvre désormais l’ensemble du spectre des intégrations Databricks directes, de l’ingestion en masse et en streaming jusqu’aux requêtes.
Serveur i3X
Les standards de connectivité industrielle se sont historiquement concentrés sur la télémétrie et le contrôle des procédés. Pour un ensemble plus large d’interactions applicatives — navigation, lectures et écritures transactionnelles, requêtes historiques — le paysage reste fragmenté. Lorsque des standards existent, leur adoption est inégale et leur implémentation varie selon les éditeurs. Chaque intégration nécessite alors un travail spécifique, et cette charge augmente avec le nombre d’applications. L’Industrial Information Interoperability eXchange (i3X) répond à ce problème en définissant une API commune, centrée sur les applications, couvrant l’ensemble de ces interactions.
La spécification i3X est développée au sein du CESMII, avec la participation d’éditeurs de logiciels industriels, d’intégrateurs systèmes et d’utilisateurs finaux de premier plan. HighByte est un contributeur actif à cette spécification, et la version 4.4 d’Intelligence Hub introduit une première implémentation de l’interface serveur i3X, faisant d’Intelligence Hub l’un des premiers produits à proposer un support i3X.
Le serveur i3X expose l’espace de noms d’Intelligence Hub — incluant à la fois l’espace de noms interne HighByte et les modèles définis par les utilisateurs — à tout client compatible i3X. Les clients peuvent parcourir, lire et s’abonner aux nœuds de l’espace de noms via une interface standard. Le serveur i3X reflète l’approche orientée API d’Intelligence Hub pour l’Industrial DataOps et vient compléter ses interfaces serveur existantes aux côtés du REST Data Server et du MCP Server. À mesure que la spécification i3X approchera de sa finalisation, l’implémentation d’Intelligence Hub sera mise à jour vers la version officielle 1.0.
Agent IA pour les pipelines
Les pipelines sont au cœur d’Intelligence Hub : ils contrôlent la manière dont les données circulent et sont traitées. Pour les équipes en début de parcours Industrial DataOps, leur configuration présente une courbe d’apprentissage. À mesure que les déploiements s’étendent et que davantage d’équipes interviennent, cette configuration doit être comprise, maintenue et transmise à des personnes qui ne l’ont pas nécessairement conçue.
La version 4.4 répond à ce besoin avec le nouvel Agent IA pour les Pipelines : un agent intégré à l’application, connecté au LLM de votre choix, qui permet de résumer, créer et modifier la configuration des pipelines de manière conversationnelle. Une fois les modifications proposées, l’interface Pipeline affiche précisément ce qui a été ajouté ou modifié. Les utilisateurs peuvent tester, déboguer, accepter ou rejeter les changements, puis poursuivre les itérations.
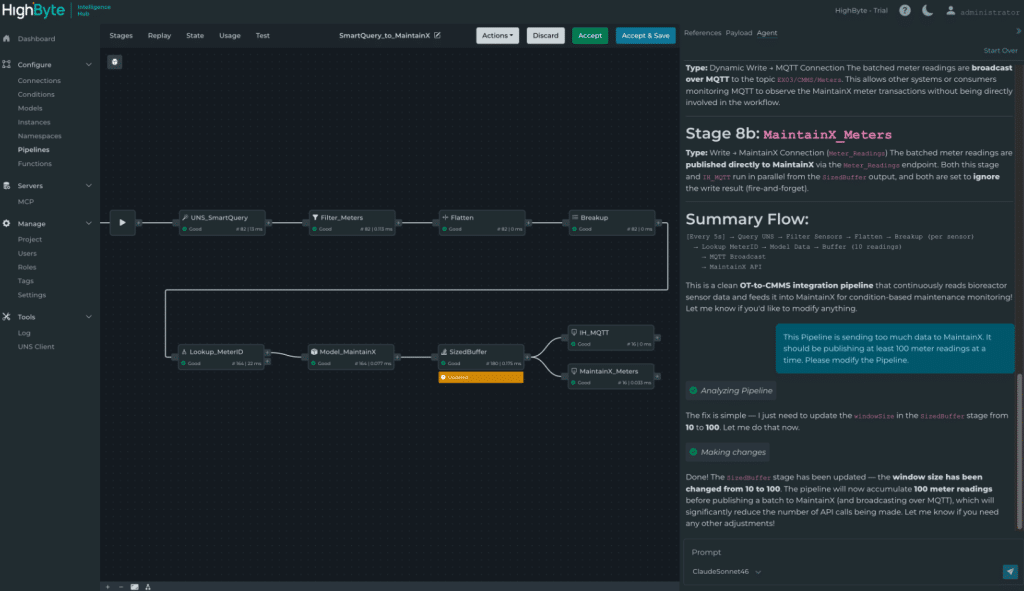
Agent IA pour les Pipelines dans HighByte Intelligence Hub version 4.4
Quelques exemples concrets d’utilisation :
- « Je débogue un pipeline créé par quelqu’un d’autre. Je ne le connais pas. Explique-moi ce que fait ce pipeline et détaille chaque étape. »
- « Je dois créer un flux de données qui s’abonne au topic de la chaudière, met en file d’attente 100 changements de données, les convertit au format Parquet et charge le fichier dans Azure Blob Storage en utilisant l’horodatage courant. »
L’Agent IA pour les Pipelines rend la configuration avancée des pipelines accessible à des équipes et à des niveaux de compétence variés, tout en conservant un contrôle humain à chaque étape.
Perspectives
HighByte Intelligence Hub version 4.4 fait progresser l’Industrial DataOps sur trois axes majeurs. Les Données Centrales et les souscriptions internes simplifient la gestion et la mise à disposition des données industrielles distribuées à l’échelle de l’entreprise. Le support natif de Databricks Zerobus et le serveur i3X renforcent l’intégration d’Intelligence Hub avec les plateformes et standards les plus stratégiques. Enfin, l’Agent IA pour les Pipelines rend leur configuration accessible à chaque membre de l’équipe.
Au-delà des fonctionnalités mises en avant ici, la version 4.4 inclut des améliorations de performance, des évolutions des Pipelines et du Store & Forward, ainsi que de nouvelles capacités pour les connexions Snowflake, AVEVA PI System, Oracle Database, OPC UA, Sparkplug et AWS.








