




100x‑problemet: Hvorfor AI agenter redefinerer din fabriks datainfrastruktur

Denne artikel er skrevet af John Harrington
Chief Product Officer hos HighByte
John Harrington er Chief Product Officer hos HighByte og fokuserer på at definere virksomhedens forretnings- og produktstrategi. Hans ansvarsområder omfatter product management, customer success, partner success og go‑to‑market‑strategi.
Da John for nylig deltog i podcasten Industrial AI, blev han introduceret som Chief Product Officer hos HighByte, hvor han arbejder med at definere virksomhedens forretnings‑ og produktstrategi. Hans ansvarsområder omfatter product management, customer success, partner success og go‑to‑market‑strategi.
I Industry 3.0 var det typisk 1 til 5 systemer, der forbrugte data fra shop floor, såsom SCADA, MES og historians. Industry 4.0 og introduktionen af Cloud øgede det til 10 til 50 systemer, inkl. datalakes, analyseplatforme, ERP‑integrationer, IoT‑tjenester og meget mere.
Med fremkomsten af agentisk AI forventer John en 100x stigning i edge‑baserede datakonsumenter.
Tusindvis af autonome AI‑agenter vil blive implementeret, hver med behov for specifikke, kontekstualiserede data leveret i realtid.
Dette er ikke en teoretisk øvelse, det er et skaleringsproblem. Og det er et problem, som de eksisterende dataarkitekturer, de fleste producenter bruger i dag, aldrig er designet til at løse.
Hvorfor AI agenter påvirker arkitektur diskussionerne
For at forstå, hvorfor så mange agenter er nødvendige, skal man se på, hvordan AI‑agenter fungerer i praksis. I modsætning til et dashboard, der henter et foruddefineret datasæt efter en tidsplan, er agenter målrettede og højt specialiserede.
For én enkelt arbejdsstation kan man eksempelvis bruge:
- en kvalitetsagent
- en vedligeholdsagent
- en planlægningsagent
- en supply chain‑agent
Hver agent kræver forskellige data, fra forskellige kilder, med forskellig kontekst.
Eksempler:
- Vedligeholdsagenten har brug for servicehistorik fra CMMS kombineret med realtids vibrationsdata fra OPC‑serveren.
- Kvalitetsagenten har brug for batchdata fra MES kombineret med inspektionsresultater.
- Supply chain‑agenten har brug for ordredetaljer fra ERP koblet med produktionshastigheder.
Gange det op med alle arbejdsstationer, alle linjer og alle sites i en virksomhed — volumen bliver hurtigt enorm.
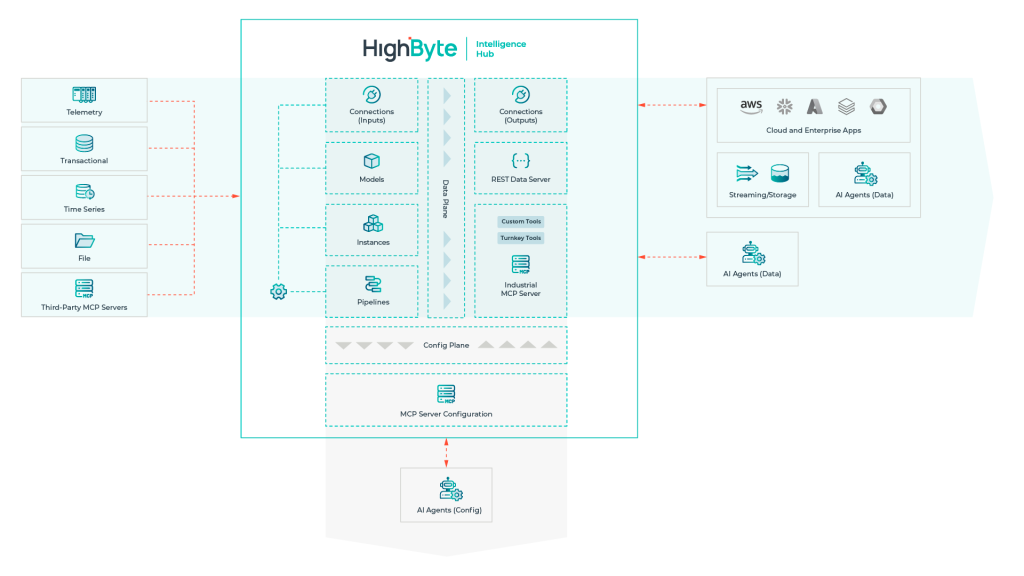
Den traditionelle ISA‑95 metode, hvor data bevæger sig lag for lag, er aldrig designet til dette. Agentisk AI har i stedet brug for en hub‑and‑spoke model, der kan forbinde til alle systemer og levere kuraterede data til alle forbrugere.
Hvad er ISA-95?
ISA‑95 er en traditionel standard for, hvordan data bevæger sig i en produktionsvirksomhed.
Grundtanken er, at data flyttes lag for lag mellem systemer — typisk struktureret sådan:
- Niveau 0–1: Maskiner, sensorer og PLC’er
- Niveau 2: SCADA og HMI
- Niveau 3: MES
- Niveau 4: ERP
Hvad er en hub-and-spoke model/tilgang?
En hub‑and‑spoke datainfrastruktur fungerer “hubben” som et centralt knudepunkt, der:
- forbinder til alle datakilder (PLC, SCADA, MES, ERP, sensorer osv.)
- samler, renser og kontekstualiserer data ét sted
- leverer “færdige dataprodukter” ud til alle forbrugere (AI‑agenter, dashboards, apps, cloud osv.)
“Spokes” er de systemer eller agenter, der får data direkte fra hubben — ikke via andre lag.
Kontekst problemet bliver kun sværere
Hvis volumen er udfordrende, er kontekst endnu mere komplekst. En rå PLC‑tag betyder intet for en AI‑agent. Hver agent kræver en kontekstpakke, der afhænger af dens mål.
Eksempler:
- En vedligeholdsagent, der analyserer en pumpe, har brug for trykdata, servicehistorik, leverandøroplysninger og batchkontekst — fra OPC‑serveren, MES, CMMS og måske ERP.
- En kvalitetsagent til samme pumpe har brug for en helt anden pakke: batch‑ID, produktspecifikationer, regulatoriske grænser og alarmhistorik.
Det er her mange AI‑initiativer går i stå. Ifølge en IDC‑rapport er 56,6% af industrivirksomheder i gang med eller planlægger at bruge AI‑agenter. Deres succes afhænger af en datastrategi, der understøtter kontekstualisering på tværs af OT‑ og IT‑systemer.
MCP: En ny protokol til en ny type konsument
Her kommer Model Context Protocol (MCP) ind i billedet. MCP er en åben protokol designet til LLM‑baserede agenter — en fundamentalt anden type datakonsument end dem, OPC UA, MQTT eller REST API’er blev bygget til.
MCP erstatter ikke eksisterende protokoller. OPC UA, SQL og MQTT fortsætter med at gøre deres arbejde. MCP samler og kontekstualiserer data fra disse kilder og eksponerer dem for agenter.
Der er dog en vigtig praktisk begrænsning:
Agenter fungerer bedst, når de har 5–10 MCP‑værktøjer, ikke hundreder. For mange værktøjer fører til fejl, forkerte valg og hallucinationer.
Det betyder, at der skal planlægges en ekstra styringsmodel, hvor agenter får tildelt specifikke opgaver og begrænsede værktøjer, men antallet af agenter vil stige eksplosivt.
Læs mere: Hvad er Model Context Protocol (MCP)?
AI og DataOps giver muligheder
Hvordan løser man så 100x‑problemet?
Den gensidige relation mellem AI og DataOps er svaret:
- DataOps for AI giver det fundament, agenter har brug for: kuraterede, kontekstualiserede og styrede data via kontrollerede pipelines.
- AI for DataOps accelererer opsætning og administration af DataOps ved at bruge AI til konfiguration og styring.
Denne dobbelte effekt betyder, at investeringer i det ene område forstærker værdien i det andet.
Hvis du undersøger DataOps i år, bør du fokusere på løsninger, der er designet specifikt til industridata. HighByte Intelligence Hub er netop sådan en løsning, med stærk støtte for MCP‑tjenester. Du kan prøve den gratis i dag.
Opsummering
Hvis din organisation evaluerer AI til produktion, skal datainfrastruktur‑samtalen ske nu. Hold disse tre punkter i mente:
- Behandl data som et førsteklasses aktiv – investér i datastrategi, byg standardiserede dataprodukter og indfør governance, der er uafhængig af applikationer og agenter.
- Adoptér en hub‑and‑spoke arkitektur – forbind til de nødvendige systemer og lever data i kontekst direkte til forbrugerne. Kontekstualisér ved Edge for lavere latenstid, lavere cloudomkostninger og højere datakvalitet.
- Planlæg for MCP – definér datatilgang, værktøjsstyring og et data control plane fra dag ét.
100x‑eksplosionen i datakonsumenter er allerede begyndt. De organisationer, der investerer i datainfrastruktur nu, bliver frontløberne. Dem, der venter, vil få svært ved at skalere AI ud over de første pilots.
Vil du vide med om HighByte Intelligence Hub?
Har du spørgsmål?
Uanset om du ønsker flere oplysninger om Intelligence Hub, eller om du har brug for en produktlicens – så giv mig besked, og jeg vender tilbage inden for 24 timer.









