


HighByte Intelligence Hub version 4.1
HighByte Intelligence Hub version 4.1 bringer kraftfulde nye funktioner til Industrial DataOps-området.
Den nyeste version gør det muligt for industrielle virksomheder at få dybere indsigt i deres drift og oprette datatjenester. Den fokuserer på forespørgselsbaserede data pipelines, datavirtualisering og avanceret filbehandling.

Industrial Data API Builder
Pipelines i HighByte Intelligence Hub var oprindeligt afhængige af Flows for at blive udløst. I version 4.0 blev Pipelines selvudløsende med mulighed for at udløses baseret på et tidsinterval eller en hændelse. I version 4.1 er Pipelines nu “kaldbare”. Dette indkapsler og abstraherer databehandling inden for en Pipeline som en simpel anmodning- og respons-tjeneste.
Inden for Intelligence Hub kan Pipelines kalde andre Pipelines for at muliggøre genbrug og deling af databehandling. Eksternt kan Pipelines eksponeres til REST Data Server, hvilket muliggør højt tilpasset datavirtualisering og on-demand databehandling. Eksterne forbrugere kan sikkert sende anmodninger til Intelligence Hub for at skubbe eller hente data gennem en Pipeline. Med denne kraftfulde nye funktion kan du opbygge tilpassede API’er til dine operations- og industrielle datakilder.
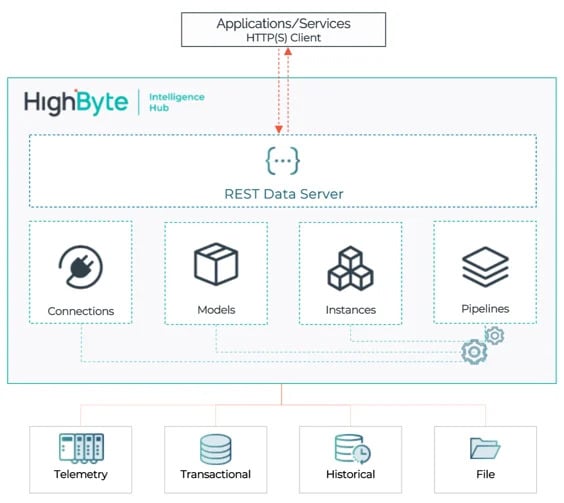
Opret datatjenester med Pipelines og eksponer dem med REST Data Server i HighByte Intelligence Hub version 4.1.
Med API-byggeren for industriel data kan brugere:
- Bygge skræddersyede API’er til deres fabrikker og forretningsprocesser
- Give programmatisk adgang til ERP- eller andre applikationer uden at gå på kompromis med sikkerhed eller performancemål
- Oprette forenklede interfaces for line-of-business brugere og business intelligence værktøjer til at hente data fra sofistikerede historians som AVEVA PI System, Aspen IP.21 og Honeywell PHD
- Oprette kompatible interfaces for aktiver og instrumentering til MES-løsninger som Körber PAS-X
- Oprette Unified Namespace-tjenester til at levere historiserede data og facilitere transaktioner
Pipeline Debug Mode
Efterhånden som pipelines fortsætter med at udvikle sig og spiller en central rolle i Intelligence Hub, er det blevet essentielt at integrere observabilitet i Pipeline Graph for at accelerere udvikling og fejlfinding.
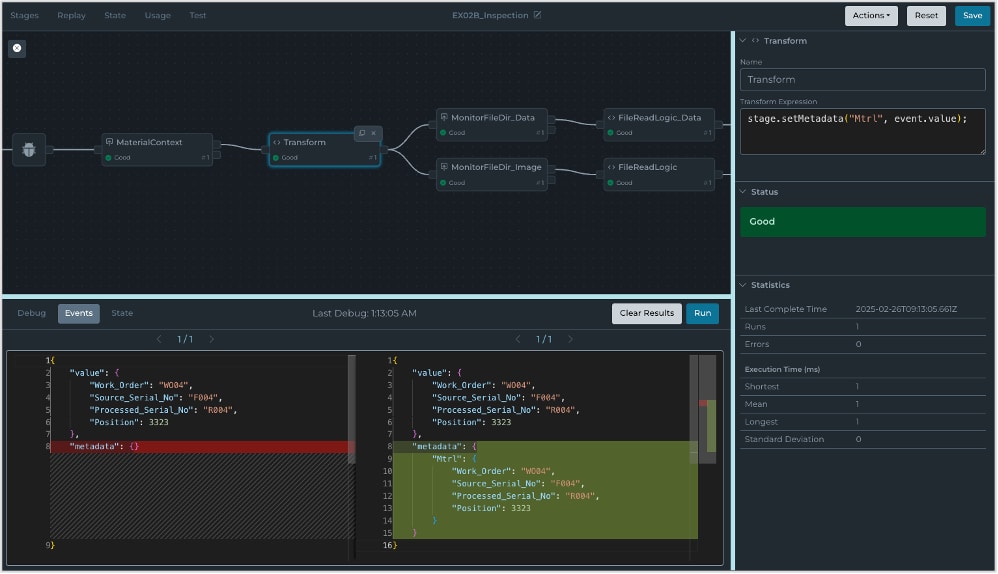
En visning i mørk tilstand af de nye Pipeline Debug-funktioner i HighByte Intelligence Hub version 4.1.
Som et supplement til de eksisterende observabilitetsfunktioner såsom Pipeline Replay introducerer Intelligence Hub version 4.1 Pipeline Debug, en ny funktion til at udføre individuel test af Pipeline Stages. Pipeline Debug giver dig mulighed for at teste virkningen af forskellige konfigurationer og indkommende event-payloads inden for en Pipeline. Du kan visuelt undersøge og sammenligne før- og eftertilstanden af en payload ved hver Pipeline Stage, hvilket forenkler pipeline-udviklingen. Ved at udnytte denne nye funktion som en del af din pipeline-oprettelses- og administrationsarbejdsgang bliver det endnu lettere at konfigurere og fejlsøge Pipelines.
Advanced Audit Logging
HighByte Intelligence Hub version 4.1 tilbyder enterprise-administrationsfunktioner, der imødekommer den stigende efterspørgsel efter skalerbar, sikker og compliant datainfrastruktur i stærkt regulerede industrier.
Fælles for disse industrier er formelle praksisser inden for ændringshåndtering, sporbarhed og ansvarlighed. Revision spiller en nøglerolle i disse processer og kræver systemer, der kan registrere detaljerede hændelser.
For at understøtte disse kritiske miljøer har vi gennemgribende forbedret revisionslogføringen i Intelligence Hub. Når konfigurationselementer opdateres via brugergrænsefladen eller programmæssigt, spiller revisionslogføring en integreret rolle i processen.
Ikke alene registreres flere ændringer, men hændelser logføres også med større detaljeringsgrad. Du kan se, hvornår en ændring blev foretaget, hvilken bruger der foretog den, hvad der blev ændret, tilstanden før og efter ændringen samt eventuelle afledte ændringer i relaterede konfigurationer. For eksempel, hvis en bruger omdøber en forbindelse, vil dette samt konsekvenserne for andre konfigurationselementer, såsom en pipeline, der bruger forbindelsen, blive logført.
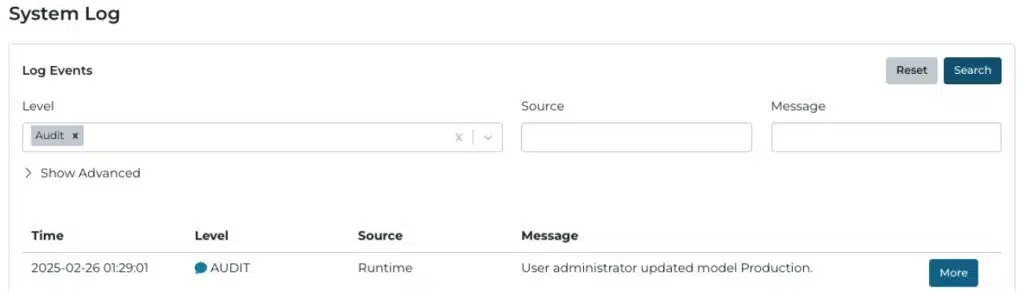
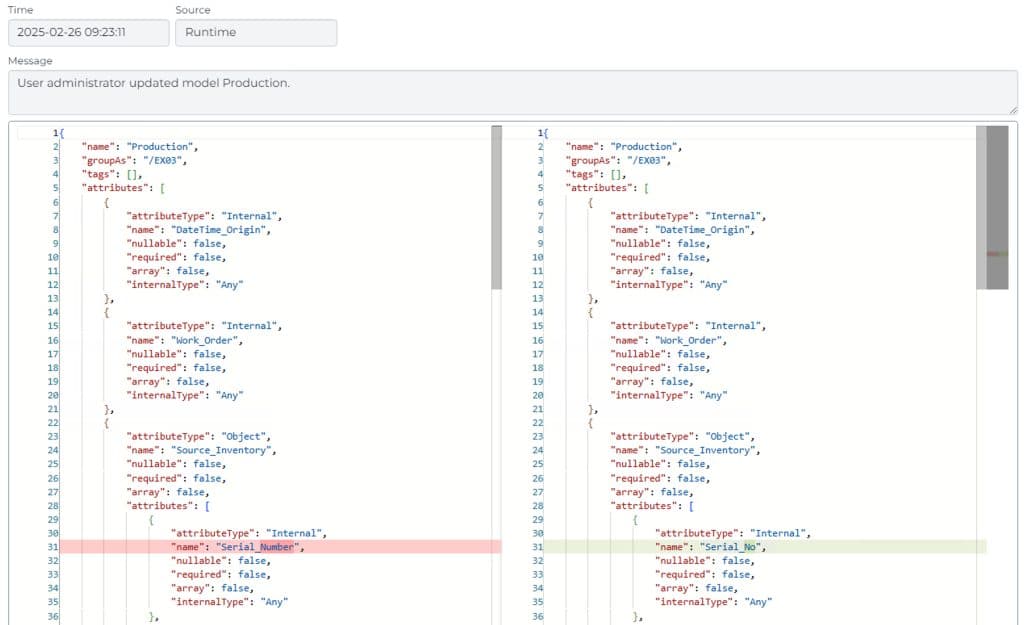
En visning af den nye Audit Log i HighByte Intelligence Hub version 4.1.
For at sikre integriteten af revisionsloggen gemmes dens indhold i en dedikeret, krypteret fil. Revisionsloggen kan vises og forespørges, med eller uden runtime-hændelser, fra Intelligence Hub-brugergrænsefladen og kan også overvåges af eksterne observabilitetsplatforme.
Opsummering
Med en forpligtelse til innovation fortsætter version 4.1 af Intelligence Hub med at skubbe grænserne for, hvad der er muligt og bør forventes af en enterprise Industrial DataOps-løsning. Nye ingeniørfunktioner og forbedrede egenskaber til stærkt regulerede industrier gør version 4.1 til et vigtigt og værdifuldt fremskridt for Intelligence Hub-brugere.
Release notes
Nye funktioner:
- Tilføjet support til at bygge brugerdefinerede API’er med Pipelines og REST Data Serveren. Pipelines kan nu markeres som kaldbare og returnere værdier eller rejse fejl.
- Tilføjet support til at kalde en Pipeline fra REST Data Serveren, en Namespace Node eller en anden Pipeline.
- Tilføjet Pipeline Debug-tilstand, der giver brugere mulighed for at fejlfinde pipelines og sammenligne før- og efterhændelser gennem stadier.
- Tilføjet en Aspen InfoPlus.21-connector med support til at gennemse skemaer og læse tags.
- Tilføjet en Amazon S3 Tables-connector med support til at skrive til og oprette S3-tabeller.
- Tilføjet abonnementsstøtte for Ignition-inputs, så de kan bruges i Event Triggers og fange live tag-opdateringer.
- Tilføjet en mørk tilstand i UI’et.
- Tilføjet en Success/Failure-sti til Read-stadiet for at understøtte brugerdefineret håndtering af læsefejl.
- Tilføjet Track Changes og Ignore Changes-indstillinger i On Change-stadiet for at muliggøre ændringssporing på attributniveau.
- Tilføjet en Branch-inputtype til MQTT for at læse flere underordnede emner som komplekse data.
- Tilføjet support til at returnere metadata med OPC UA Branch- og Collection-inputs.
- Tilføjet support til at klone stadier i en Pipeline.
- Forbedret MQTT-output ved at gruppere hurtigt offentliggjorte beskeder, hvilket forbedrer ydeevnen for QOS 1- og QOS 2-skrivninger.
- Forbedret MSSQL CDC Input, så tabelnavne kan præfikseres med deres tilsvarende skema.
- Tilføjet support til at indstille brugerdefinerede headers for Kafka-outputs.
- Forbedret Input-cache, så den ryddes efter, at input er gemt.
- Tilføjet support til Ignition-connectoren for at læse og abonnere på UDT-instanser.
- Forbedret audit-logning for at understøtte indfangning og visning af før- og efterændringer samt kaskadeændringer.
- Tilføjet en Cron-trigger til at planlægge eksekvering af en Pipeline.
- Tilføjet en Subpipeline-stage, der kan bruges til at kalde pipelines, der udfører fælles funktioner.
- Tilføjet support til at overføre parametre til Namespace Nodes, så parameteriserede kilder kan bruges i namespaces.
- Tilføjet support til at læse og skrive filer over SFTP med File-connectoren.
- Tilføjet support til at trække Referencer over på Instans-attributter i trævisningen.
- Tilføjet en advarsel til Pipeline-polled triggers i tilfælde, hvor triggeren afstemmer hurtigere, end pipelinen kan behandle hændelsen. I dette tilfælde sænker triggeren afstemningen for at matche pipeline-eksekveringen.
- Tilføjet support til at bygge og teste smarte forespørgsler i Namespaces.
- Tilføjet support til at bruge dynamiske indstillinger i Smart Query-stadiet i Pipelines.
- Forbedret ydeevnen for Write og Write New-stadier, når “Ignore Return” anvendes.
- Forbedret styling af Input- og Output-siderne.
- Tilføjet support til at læse tidszoneværdier med Oracle SQL-inputs.
- Tilføjet support til at autentificere REST-forbindelser med OAuth 2.0 password grant type.
- Tilføjet support til at læse og skrive med AMQP Over WebSocket på Azure Event Hubs-connectoren.
- Tilføjet support til at gennemse og læse mapper med File-connectoren.
- Forbedret metadata for File-input, så det nu inkluderer oprettelsestidspunkt, opdateringstidspunkt og filstørrelse.
- Tilføjet support til at filtrere File Input-læseresultater baseret på filens oprettelses- og opdateringstid.
- Tilføjet support til at læse filer som tekst med File-connectoren.
- Tilføjet Parse-stadier til at dekode CSV-, JSON-, Parquet- og XML-data fra filer eller strenge inden for en Pipeline.
- Tilføjet en Format XML-stage til konvertering af JSON til XML som fil- eller strengbaseret payload.
- Forbedret Write og Write New-stadier med “Ignore Return” for at rapportere forsinkede skrivefejl til Pipeline.
- Tilføjet en konfigurerbar session-timeout for automatisk at logge autentificerede brugere ud.
- Tilføjet support til at autentificere mod REST Data Serveren med Intelligence Hub-legitimationsoplysninger (skal aktiveres manuelt og er deaktiveret som standard).
- Forbedret UNS-klienten, så emner vises i alfabetisk rækkefølge.
- Tilføjet support til gruppering af betingelser og forbindelser.
- Forbedret instansattributter af typen Reference, så de kan redigeres manuelt.
- Tilføjet understøttelse af arrays og datasæt til Ignition-forbindelsen.
- Forbedret skriveydelsen for Ignition-forbindelsen i oprettelsestilstand.
- Forbedret Active Directory LDAP til at bruge paginering for store forespørgsler.
- Forbedret SAML til at understøtte et brugerdefineret variabelnavn til mapping af roller i Intelligence Hub.
Rettelser:
- Rettede en fejl, hvor Azure IoT Hub-forbindelsen rapporterede forbindelsesfejl under SAS-tokenfornyelse.
- Rettede en fejl, der forhindrede brugere i at bruge kommaer i deres referenceparameter-værdier.
- Rettede et problem, hvor højfrekvent pipeline-replay-aktivitet ikke blev returneret i den rækkefølge, den blev genereret i replay-tilstand.
- Tilføjede SQL input-skabelonsiden igen.
- Rettede en fejl, hvor både læse- og eksekveringsrettigheder var påkrævet for at læse instansdata. Nu kræves kun eksekveringsrettigheder.
- Rettede en fejl, hvor tag-baserede tilladelser blev ignoreret ved læsning af inputdata.
- Rettede en hukommelseslækage forårsaget af ikke-lukkede JavaScript-udtryksressourcer.
- Rettede et problem, hvor InfluxDB-skrivninger ikke korrekt escape’ede strenge med mellemrum.
- Rettede en fejl, hvor PI System-skrivninger fejlede på grund af asset-navne med foranstillede mellemrum.
- Rettede en fejl, hvor CSV- og Parquet-inputs ikke viste standardværdien for maksimalt antal rækker pr. læsning.
- Rettede en fejl, hvor Ignition-outputs ikke respekterede tidszoneforskydninger for DateTime-tags.
Breaking Changes:
- Ændrede metadata-fejl-nøglen i pipeline write-stadiet fra “writeFailures” til “writeResults”.
- Fjernede Named Root-support for REST Data Server output-skrivninger.
Sikkerhedsopdateringer:
Snowflake SQL
- CVE-2025-24789: Problem med Snowflake JDBC 4-driveren ved autentificering på Windows med EXTERNALBROWSER-autentificeringstilstand.
Parquet Connection
- CVE-2024-47561: Sikkerhedsbrist i Apache Avro SDK, der potentielt kunne føre til vilkårlig kodeudførelse.
Webapplikation
- CVE-2024-21538: Utilstrækkelig input-sanitization kunne føre til et Regular Expression Denial of Service (ReDOS)-angreb.
- CVE-2024-21539: Utilstrækkelig input-sanitization kunne føre til et Regular Expression Denial of Service (ReDOS)-angreb.








