


HighByte Intelligence Hub Version 4.4

HighByte er nu klar med version 4.4, der introducerer en række markante forbedringer på tværs af dataintegration, pipeline‑udvikling og industrielle forbindelsesmetoder.
Denne version styrker platformens rolle som central komponent i moderne, skalerbare industrielle dataarkitekturer og giver virksomheder nye muligheder for at konsolidere, strukturere og distribuere data på tværs af komplekse miljøer.
Version 4.4 leverer funktioner, der hjælper industrivirksomheder med at føderere namespaces, bygge pipelines med AI‑assistance i appen og udnytte innovative forbindelsesmetoder.
Vigtigste opdateringer i HighByte Intelligence Hub 4.4
Central Data
Siden version 3.0 har Intelligence Hub inkluderet Central Configuration, som giver mulighed for sikkert at forbinde fjern-hubs til en central hub og administrere deres konfiguration. Siden introduktionen af Namespaces i version 4.0 har brugere efterspurgt måder at føderere namespaces fra fjerntliggende hubs ind i en central hub. Version 4.4 adresserer dette med Central Data.
Central Data udvider konceptet Central Configuration ved at eksponere dataplanen fra én hub til en central hub. Når forbindelsen er etableret, kan den centrale hub se namespace’et for hver fjern-hub og mappe deres noder ind i et fælles centralt namespace. Brugere kan browse dette namespace, køre Smart Queries og opbygge Pipelines, der abonnerer på og trækker data fra fjernkilder, som om de var lokale.
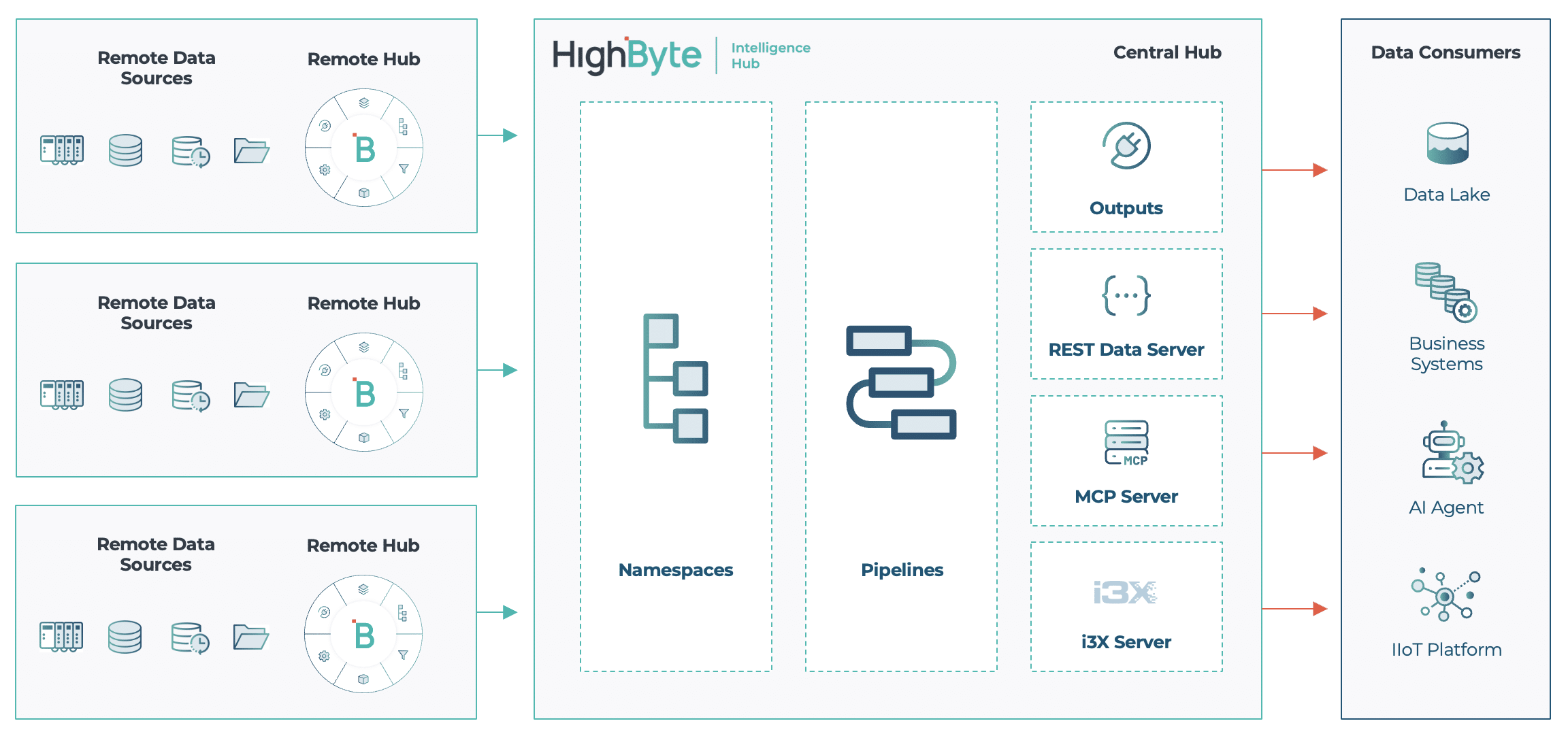
Central Hub i HighByte Intelligence Hub version 4.4
Central Data i HighByte Intelligence Hub version 4.4
For at gøre det konkret:
En enkelt Pipeline kan udføre en Smart Query på tværs af kontekstualiserede datasæt fra flere fjern-hubs, abonnere på relevante målinger til tilstandsbaseret vedligehold, forme dataene så de matcher MaintainX‑API’et og publicere direkte til MaintainX – alt sammen fra én hub, der fungerer på vegne af mange distribuerede datakilder på tværs af netværksgrænser.
Central Data forenkler distribuerede arkitekturer ved at muliggøre et fælles sæt pipelines, der kan betjene enterprise-datamål fra én enkelt hub, hvor alle modellerede fabriksdata er søgbare og handlingsklare efter behov.
Interne abonnementer
Intelligence Hub har siden første version understøttet abonnementer på hændelsesdrevne kilder som OPC UA og MQTT. Efterhånden som datamodeller og datapipelines bliver mere sofistikerede, opstår der imidlertid behov for at abonnere på ændringer i komplekse objekter som Model-Instances, der kan være sammensat af både hændelsesdrevne og ikke-hændelsesdrevne kilder.
Version 4.4 introducerer abonnementssupport for komplekse objekter, herunder Instances, Namespaces samt OPC UA‑grene og -samlinger. Ved hjælp af nye pipeline-triggere genereres der automatisk events, når de underliggende kildedata ændrer sig. For eksempel: Hvis en Instance er sammensat af OPC UA-tags og SQL-data, oprettes der et event, når OPC-tagene ændres, og payloaden indeholder samtidig de seneste værdier hentet fra SQL. Abonnementer fungerer også på namespaces – inklusive noder, der er fødereret via Central Data – og genererer events til pipeline’en, når nodeværdier ændres.
Denne nye funktionalitet forenkler pipeline-designet, eliminerer behovet for polling efter ændringer og sikrer, at dataændringer aldrig overses – på tværs af både lokale og distribuerede datakilder.
Fremdrift i industriel konnektivitet
Det industrielle datalandskab formes af de centrale platforme, som organisationer har investeret i, samt de åbne standarder, der definerer, hvordan systemer forbindes. Dybden af integration med disse platforme – fra batch- og streaming-indlæsning til forespørgsler og agent-baseret adgang – er det, der adskiller overfladisk konnektivitet fra reel forretningsmæssig effekt.
Åbne standarder er lige så vigtige, da de reducerer det ikke-differentierende udviklingsarbejde og de samlede ejeromkostninger for alle involverede.
Lederskab inden for konnektivitet betyder at være på forkant på begge fronter: at understøtte de platforme, hvor arbejdet udføres, og at fremme åbne standarder, der omsættes til reel anvendelse. Version 4.4 gør begge dele.
Databricks Zerobus
Databricks er blevet en af de mest udbredte platforme til analyse- og AI‑workloads, og Intelligence Hub har opbygget omfattende integration på tværs af hele spektret af interaktionsmønstre. Til indlæsning understøtter Intelligence Hub bulk-load via objektlagring samt direkte bulk via Databricks Storage‑forbindelsen. Til forespørgsel og reverse ETL muliggør Databricks SQL‑forbindelsen direkte adgang fra Databricks tilbage til OT‑systemer. Streaming‑indlæsning har også været understøttet, men har tidligere krævet, at data blev routet via en mellemliggende event‑streaming‑tjeneste som Amazon Kinesis Data Streams, Azure Event Hubs eller Apache Kafka, før de nåede Databricks.
Databricks Zerobus ændrer dette. Det er et nyt serverløst streaming‑indlæsningsinterface, der muliggør indlæsning af data post‑for‑post direkte i Delta‑tabeller. Version 4.4 introducerer en indbygget Zerobus‑forbindelse i Intelligence Hub, som gør direkte streaming‑indlæsning med lav latenstid til Databricks mulig – uden nogen mellemliggende tjeneste. Tabeller oprettes, og skemaer udvikles automatisk baseret på modeldefinitioner. Data lander direkte i Delta Lake og er straks synlige i Unity Catalog.

Direkte Databricks-integrationer i HighByte Intelligence Hub version 4.4
Med den nye Databricks Zerobus‑forbindelse dækker Intelligence Hub nu hele spektret af direkte Databricks‑integration – fra bulk‑ og streaming‑indlæsning til forespørgsler.
i3X Server
Industrielle konnektivitetsstandarder har i vid udstrækning fokuseret på telemetri og processtyring. For det bredere sæt af interaktioner, som applikationer har behov for – herunder browsing, transaktionelle læse- og skriveoperationer samt historiske forespørgsler – er landskabet fragmenteret. Hvor standarder findes, har adoptionen været ujævn. I praksis implementerer hver leverandør standarderne forskelligt. Hver integration kræver specialtilpasning, og denne byrde vokser i takt med antallet af applikationer. Industrial Information Interoperability eXchange (i3X) adresserer dette ved at definere et fælles, applikationscentreret API, der dækker alle disse interaktionsmønstre.
i3X‑specifikationen udvikles gennem CESMII med deltagelse fra førende industrielle softwareleverandører, systemintegratorer og slutbrugere. HighByte er en aktiv bidragyder til specifikationen, og version 4.4 af Intelligence Hub introducerer en tidlig implementering af i3X Server‑interfacet, hvilket gør Intelligence Hub til et af de første produkter med i3X‑understøttelse.
i3X Server eksponerer Intelligence Hub‑namespace’et – inklusive både det interne HighByte‑namespace og brugerdefinerede modeller – til enhver i3X‑kompatibel klient. Klienter kan browse, læse og abonnere på namespace‑noder via et standardiseret interface. i3X Server afspejler Intelligence Hubs API‑centrerede tilgang til Industrial DataOps og udvider de eksisterende standardserverinterfaces sammen med REST Data Server og MCP Server. Efterhånden som i3X‑specifikationen nærmer sig en endelig version, vil Intelligence Hubs implementering blive opdateret til den officielle v1.0‑udgave.
Pipeline AI Agent
Pipelines er kernen i Intelligence Hub og styrer, hvordan data bevæger sig og behandles. For teams, der er tidligt i deres Industrial DataOps‑rejse, er der en indlæringskurve i forhold til at forstå, hvordan pipelines konfigureres. Efterhånden som udrulninger vokser, og flere teams involveres, bliver det nødvendigt, at konfigurationen kan forstås, vedligeholdes og overdrages til personer, som ikke selv har bygget den.
Version 4.4 adresserer dette med den nye Pipeline AI Agent – en in‑app‑agent, der forbindes til brugerens foretrukne LLM og gør det muligt via samtale at opsummere, oprette og redigere Pipeline‑konfiguration. Når agenten foreslår ændringer, viser Pipeline‑UI’et præcist, hvad der er tilføjet eller ændret. Brugere kan debugge og teste ændringerne og derefter acceptere eller afvise dem og fortsætte iterativt.
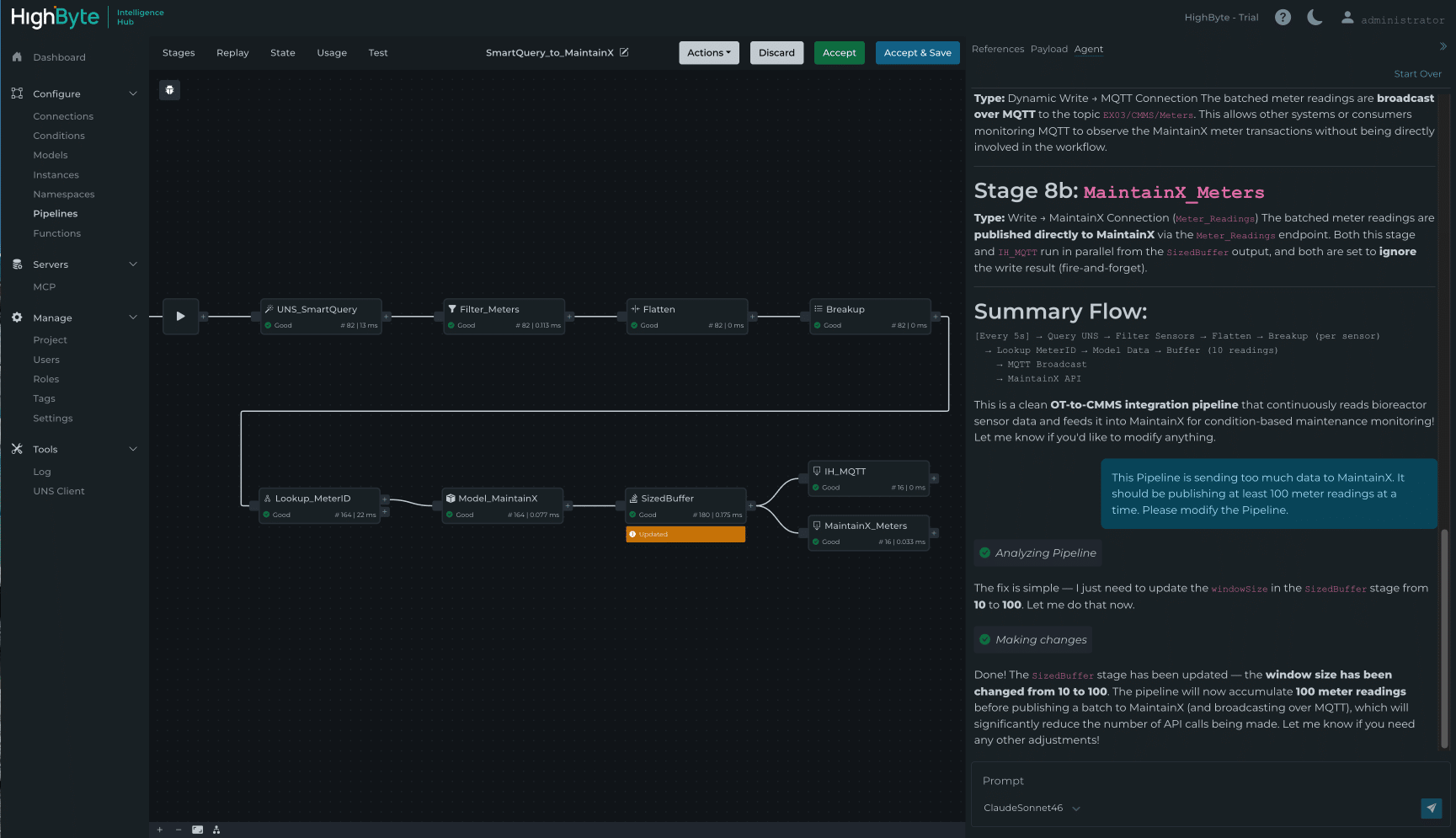
Pipeline AI Agent i HighByte Intelligence Hub version 4.4
Eksempler på, hvordan det kan se ud i praksis:
- “Jeg fejlsøger en Pipeline, som en anden har bygget. Jeg er ikke bekendt med den. Forklar, hvad denne Pipeline gør, og gennemgå hvert trin.”
- “Jeg skal oprette et dataflow, der abonnerer på kedel‑topic’et, køer 100 dataændringer, konverterer dem til parquet‑format og uploader filen til Azure Blob Storage med det aktuelle timestamp.”
Pipeline AI Agent gør sofistikeret Pipeline‑konfiguration mere tilgængelig på tværs af teams og kompetenceniveauer – med menneskelig beslutningskraft i loopet ved hvert trin.
Fremadrettet
HighByte Intelligence Hub version 4.4 fremmer Industrial DataOps på tre områder. Central Data og interne abonnementer forenkler, hvordan distribuerede industrielle data håndteres og stilles til rådighed på tværs af virksomheden. Indbygget Databricks Zerobus‑understøttelse og i3X Server styrker integrationen med de platforme og standarder, der er mest afgørende. Og Pipeline AI Agent gør Pipeline‑konfiguration mere tilgængelig for alle i teamet.
Ud over de funktioner, der er fremhævet her, inkluderer version 4.4 også performance‑forbedringer, forbedringer af Pipelines og Store & Forward samt nye muligheder på tværs af Snowflake, AVEVA PI System, Oracle Database, OPC UA, Sparkplug og AWS‑forbindelser.
Vil du høre mere om HighByte Intelligence Hub?
Har du spørgsmål?
Uanset om du ønsker flere oplysninger om Intelligence Hub, eller om du har brug for en produktlicens – så giv mig besked, og jeg vender tilbage inden for 24 timer.









